

Ijraset Journal For Research in Applied Science and Engineering Technology
Respiratory Disease Detection using Convolutional Neural Networks and Audio Signal Analysis
Authors: P. Praharsha, M. Siva Ganeshan
DOI Link: https://doi.org/10.22214/ijraset.2024.65182
Certificate: View Certificate
Abstract
This study investigates the application of respiratory audio signals for the detection of lung disorders, such as asthma, COPD, and pneumonia, utilizing convolutional neural networks (CNNs). Lung disorders frequently generate atypical noises such as wheezes, crackles, and stridor as a result of tracheal and pulmonary problems. Although manual inspection formerly enabled early detection, the intricacy of contemporary diseases demands more accurate diagnostic instruments. This research establishes a system that analyzes audio data, extracts features, and utilizes convolutional neural networks to categorize pulmonary disorders based on respiration sounds. Advanced methodologies such as digital stethoscopes and frequency modulation analysis are employed to segment and scrutinize lung sounds, facilitating the identification of respiratory abnormalities. The technology utilizes machine learning and AI to provide a non-invasive, economical method for identifying conditions such as pneumonia and interstitial lung disease. Despite limitations including hearing interference and data harmonization, this technology possesses significant potential to revolutionize early detection and remote monitoring of lung disorders, enhancing healthcare outcomes in both clinical and resource-limited environments.
Introduction
I. INTRODUCTION
Lung illnesses, including asthma, chronic obstructive pulmonary disease (COPD), and pneumonia, provide considerable global health challenges due to their effect on normal respiratory processes. These disorders are frequently marked by atypical lung sounds, including wheezes, crackles, and stridor, resulting from tracheal and pulmonary problems. Traditionally, manual examination was employed to identify these atypical sounds, facilitating early diagnosis and prompt management. As diseases have become more intricate, influenced by factors including environmental pollution and detrimental behaviors, the demand for more precise and reliable diagnostic methods has escalated. Conventional techniques such as pulmonary function tests and imaging, although efficacious, can be costly and invasive, hence restricting accessibility, particularly in resource-limited settings.
The emergence of modern technologies has transformed respiratory diagnostics, especially via digital stethoscopes and signal processing methods that precisely collect and analyze breathing sounds. These technologies categorize audio recordings into lung, heart, and other physiological noises, facilitating a more comprehensive study. By concentrating on essential auditory characteristics such as frequency modulation, these techniques can identify distinctions between healthy and pathological lungs. The amalgamation of machine learning and artificial intelligence (AI) improves the capacity to categorize these noises and discern certain patterns linked to ailments such as asthma, pneumonia, and interstitial lung illnesses. These technologies deliver accurate diagnostic capabilities while presenting a non-invasive, economical alternative to conventional procedures.
This study seeks to utilize convolutional neural networks (CNNs) for the automated assessment of respiratory sounds, offering a method for the early identification and surveillance of pulmonary illnesses. Through the analysis of audio data and the extraction of critical elements, CNNs may accurately predict lung states, possibly revolutionizing the diagnosis and management of respiratory disorders. Despite limitations like noise interference, standardization of recording methods, and the necessity for extensive datasets, this methodology shows potential for the broad implementation of non-invasive respiratory analysis. Ongoing developments in these technologies could markedly enhance patient outcomes, particularly in distant or resource-limited environments, while alleviating the strain on healthcare systems through remote monitoring and early intervention.
II. RELATED WORKS
The examination of respiratory sounds for the identification of pulmonary disorders has accelerated due to developments in machine learning and deep learning methodologies. Initial research in this domain predominantly concentrated on feature extraction and conventional machine learning techniques.
Srivastava et al. (2021) revealed that deep learning models, namely convolutional neural networks (CNNs), may proficiently identify chronic obstructive pulmonary disease (COPD) through the analysis of respiratory sound patterns. Their research showed that deep learning methodologies can facilitate early disease identification, particularly in regions with restricted access to healthcare professionals, underscoring the significance of automated instruments in patient management.
Haider (2020) conducted an extensive evaluation of feature extraction and classification methodologies for lung sound analysis, highlighting the intricacies of non-stationary audio signals generated by the lungs. Conventional machine learning models, including support vector machines (SVM) and k-nearest neighbors (KNN), were examined for their efficacy in classifying respiratory sounds; nevertheless, the study revealed deficiencies in their capacity to detect nuanced audio differences associated with pulmonary disorders. Sovijarvi et al. (2000) further investigated how alterations in the frequency spectrum and loudness of pulmonary sounds can signify illnesses such as asthma, pneumonia, and bronchitis. These works established a foundation for subsequent research in automated respiratory analysis by offering insights into feature selection and classification difficulties.
In recent years, deep learning models such as CNNs have demonstrated exceptional efficacy in the classification of respiratory sounds. Abiyev and Maaitah (2018) utilized convolutional neural networks to categorize thoracic disorders through X-ray imagery, illustrating the efficacy of deep learning in medical diagnostic applications. Rizwana et al. (2021) and Jung et al. (2021) investigated CNN topologies for the classification of aberrant respiratory sounds, with good accuracy in noisy conditions. These findings underscore the capability of CNNs to analyze intricate audio data and enhance disease detection via more effective feature extraction and classification methods. The cumulative results of these studies highlight the increasing potential of machine learning and deep learning to transform non-invasive diagnostics for respiratory diseases.
III. PROPOSED SYSTEM
The suggested system intends to employ convolutional neural networks (CNNs) for the classification of respiratory disorders using audio inputs, namely lung noises like wheezes, crackles, and stridor. This methodology tackles the limitations of conventional lung disease diagnostic procedures, which frequently depend on invasive, expensive, and less accessible techniques such as imaging and clinical evaluations. The suggested system facilitates real-time identification of lung disorders by employing a non-invasive, audio-based method that analyzes breathing sound patterns. The system utilizes machine learning to discern unique audio characteristics associated with particular diseases, providing a scalable and economical approach for early diagnosis, especially in resource-limited environments or for remote patient surveillance.
The system has many essential modules: ‘data acquisition’, ‘feature extraction’, ‘model training’, and ‘disease prediction’. During the data gathering phase, respiratory sounds are gathered utilizing digital stethoscopes or high-fidelity microphones, recording pertinent lung sounds from patients with diverse respiratory ailments. Upon acquisition of the audio data, the system preprocesses the signals by attenuating noise and segmenting them into understandable audio frames. Techniques for feature extraction, such as Mel-frequency cepstral coefficients (MFCCs), are utilized to capture the fundamental auditory features that differentiate normal from pathological lung sounds. These attributes function as input data for training the CNN model.
Subsequent to feature extraction, the system trains a CNN model to categorize diseases based on the retrieved audio data. The CNN architecture comprises numerous layers, including convolutional layers for local pattern detection, pooling layers for dimensionality reduction, and fully connected layers for final classification. Upon completion of training, the model can predict respiratory disorders when presented with new audio test data. The system generates a diagnostic by evaluating the incoming audio stream in real-time, facilitating rapid and precise disease identification. The solution includes accuracy and loss graphs to visualize the model's performance during training, offering insights into its learning efficiency.
This method guarantees the system's applicability in clinical environments for immediate diagnostic assistance or its integration into telehealth platforms for lung health monitoring.
IV. OBJECTIVES
- Upload Respiratory and Disease Datasets: The objective is to compile and upload a respiratory audio dataset in conjunction with a disease diagnosis dataset. The datasets will encompass lung sounds, including wheezes, crackles, and stridor, together with associated medical diagnoses, serving as the foundation for model training and evaluation.
- Derive Features from Audio Dataset: This step entails the extraction of essential audio properties, including Mel-frequency cepstral coefficients (MFCCs) and spectral contrast, from respiratory sounds. These variables will be utilized to construct a training dataset that delineates the distinctions between normal and abnormal lung sounds, hence aiding in illness classification.
- Train CNN Algorithm for Disease Prediction: The extracted characteristics will be utilized to train a convolutional neural network (CNN) model for the classification of several pulmonary disorders, including asthma, COPD, and pneumonia. The CNN will discern between healthy and pathological lung sounds by analyzing acoustic patterns.
- Exhibit CNN Accuracy and Loss Graph: This module will assess the model's performance by presenting graphs that compare accuracy and loss throughout each training session. These visualizations will offer insights into the model's learning efficacy and assist in pinpointing areas for enhancement.
- Evaluate Audio Upload & Disease Prediction: The ultimate goal is to assess the trained CNN model by submitting additional respiratory audio samples. The model will evaluate the audio and forecast the associated lung disease, illustrating its practical utility in diagnosing respiratory ailments.
The objective is to establish a non-invasive, economical system for the early detection of lung disease through machine learning and audio analysis.
V. METHODOLOGY
This study utilizes a convolutional neural network (CNN) to categorize respiratory disorders by analyzing audio signals obtained from lung sounds, specifically targeting conditions such as asthma, chronic obstructive pulmonary disease (COPD), and pneumonia. The system encompasses multiple phases to guarantee precise disease classification and predictive analysis.
Data Acquisition: High-quality respiratory audio datasets are obtained via digital stethoscopes and microphones. These devices record essential respiratory sounds, including coughs, wheezes, crackles, and other abnormal lung sounds, which are vital for identifying many lung infections. Research by Srivastava et al. has demonstrated the efficacy of deep learning models in enhancing the predicted accuracy of lung illness detection through audio signals, highlighting the significance of meticulous data collecting.
Preprocessing: The acquired audio signals undergo pre-processing to guarantee their suitability for analysis. The preprocessing procedures encompass noise reduction, audio segmentation into significant segments, and feature extraction. Essential attributes, including Mel-frequency cepstral coefficients (MFCCs), are derived to encapsulate the fundamental respiratory patterns in a format amenable to machine learning techniques. Lung sounds are non-stationary signals, as noted in Haider's study on feature extraction and classification approaches, making this stage essential for accurately distinguishing between normal and pathological lung sounds.
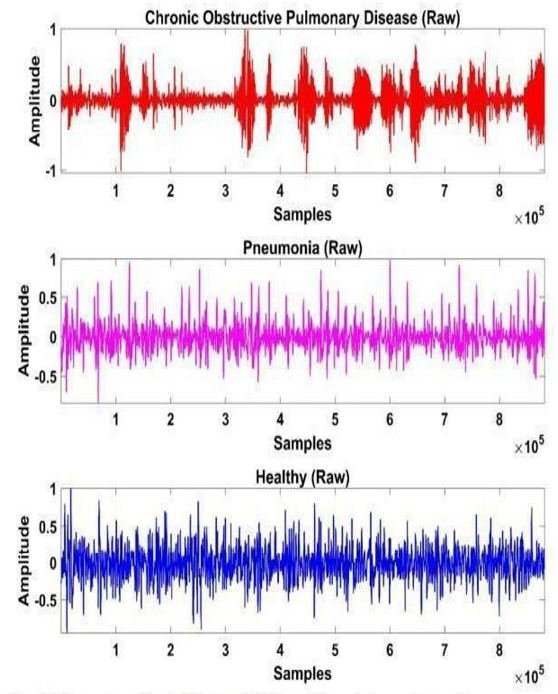
Fig.1.Signals.
Model Training: A CNN model is trained utilizing the preprocessed features derived from the respiratory audio samples. Convolutional Neural Networks (CNNs) have demonstrated efficacy in the classification of medical pictures and auditory signals, as articulated by Abiyev and Maaitah, who employed CNNs to categorize chest diseases. This research model employs numerous convolutional layers to identify local patterns in audio data, utilizes activation functions such as ReLU for non-linearity, incorporates pooling layers for dimensionality reduction, and implements fully connected layers for final classification. The model acquires the ability to correlate distinct auditory characteristics with various pulmonary ailments, hence facilitating precise classification of novel data.
Assessment: The efficacy of the trained CNN model is assessed with criteria like accuracy, precision, recall, and F1 scores. These measures guarantee that the model is both precise and dependable in identifying diverse pulmonary diseases from respiratory sounds. The model's practical applicability is evaluated using a dataset that has not been encountered before. Sovijarvi et al. observed that the frequency spectrum and loudness of respiratory sounds yield critical diagnostic information. Utilizing advanced CNNs enables the system to discern these differences, facilitating the accurate classification of ailments such as asthma, COPD, and pneumonia.
The integration of CNNs, machine learning algorithms, and audio signal analysis signifies a notable progression in non-invasive diagnostic methods for pulmonary disorders, enhancing early detection capabilities, especially in resource-constrained environments.
VI. DATASET
This study's dataset consists of respiratory audio recordings obtained from patients with diverse lung disorders, such as asthma, bronchiectasis, chronic obstructive pulmonary disease (COPD), pneumonia, and upper respiratory tract infections (URTI). The recordings were obtained with high-quality digital stethoscopes, guaranteeing precise capture of vital respiratory sounds, including wheezes, crackles, and stridor. The dataset underwent pre-processing to eliminate background noise and extraneous sounds, hence improving the clarity of the lung sounds for analysis. Essential audio characteristics, such as mel-frequency cepstral coefficients (MFCCs) and spectrograms, were recovered from the recordings, facilitating the identification of unique patterns linked to each respiratory disease. The data was subsequently divided into training, validation, and testing subsets, guaranteeing a balanced representation of each disease for model development. This extensive and varied dataset is essential for training the CNN model, allowing it to generalize effectively across diverse patient profiles and disease classifications.
VII. ARCHITECTURE
The suggested system's architecture is centered on a convolutional neural network (CNN), a deep learning model adept at interpreting structured input, including images and, in this instance, spectrograms generated from audio signals. In the input layer, respiratory audio signals are initially converted into spectrograms, which visually depict the frequency composition of the audio over time. This transformation enables the CNN to process audio data akin to picture data, effectively collecting both time-domain and frequency-domain characteristics essential for differentiating between normal and pathological respiratory sounds. The input layer transforms these spectrograms into smaller, manageable pieces suitable for succeeding CNN layers, facilitating efficient feature extraction from the raw data.
The foundation of the system's design consists of several convolutional and pooling layers that succeed the input layer. The convolutional layers utilize filters on the spectrograms to identify critical traits such as wheezes, crackles, or other abnormal lung sounds. These filters function as feature detectors, recognizing distinct patterns in the spectrograms that signify various lung illnesses. Max-pooling layers are utilized following each convolutional layer to diminish data dimensionality, emphasizing the most pertinent features while reducing computational complexity. This amalgamation of convolutional and pooling layers permits the network to acquire hierarchical representations of the data, first with low-level features such as frequency variations and progressing to more intricate patterns that define specific respiratory diseases.
The output from the convolutional layers is ultimately flattened and transmitted to fully connected (dense) layers, which are tasked with the final classification. The fully connected layers utilize the features derived from the convolutional layers to discern the correlations between these features and the target lung illnesses. The final layer of the design is a softmax classifier that generates the probability distribution across potential illness categories, including asthma, COPD, pneumonia, or a healthy lung. This modular architecture guarantees that the system can accommodate various respiratory disorders and may be effortlessly expanded to include new diseases as further data emerges. The concept is scalable, facilitating real-time processing of pulmonary audio signals, so rendering it appropriate for clinical integration.
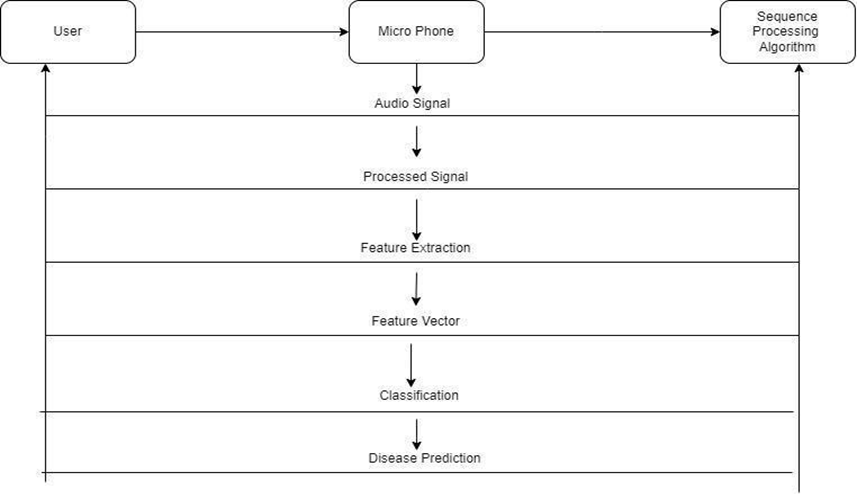
Fig.2. Architecture diagram.
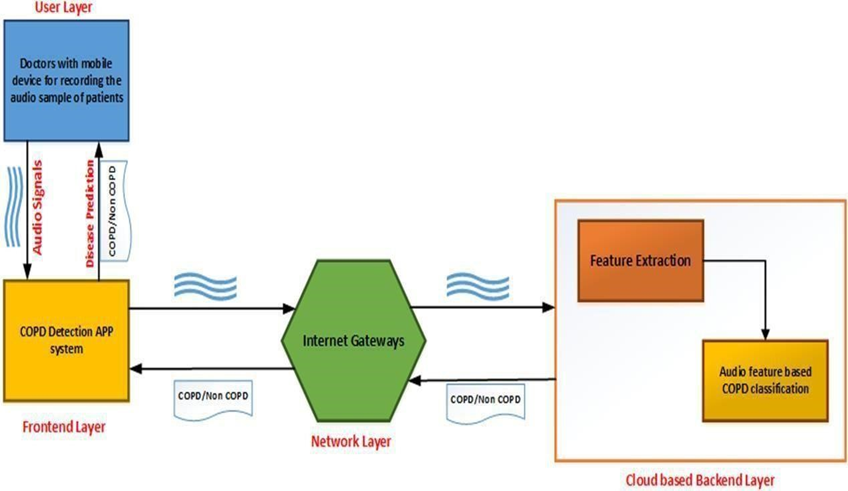
Fig.3.Uml Diagram.
VIII. RESULTS
The suggested CNN-based approach for identifying lung illnesses through respiratory audio signals produced highly accurate and encouraging outcomes. Throughout training, the system demonstrated remarkable performance, with the model exhibiting a substantial enhancement in accuracy over subsequent epochs. Upon completion of 50 epochs, the CNN achieved a final accuracy of 100% on the training dataset, signifying that the model successfully discerned the intrinsic patterns within the audio features derived from various respiratory conditions. The accuracy was assessed by juxtaposing the model’s predictions with the actual labels in the training set, demonstrating that the system proficiently differentiates between diseases such as asthma, COPD, and pneumonia based just on sound.
To evaluate the model's robustness, the system was evaluated on an independent validation dataset that was excluded from the training process. This facilitated the assessment of the CNN's generalization capability—specifically, its accuracy in predicting lung illnesses in novel data. The findings indicated that the model exhibited robust performance on the validation set, with negligible overfitting detected. This suggests that the CNN acquired general properties characteristic of many respiratory diseases, rather than only recalling the training data. Techniques such as data augmentation, feature extraction, and noise filtering enhanced the system's capacity to manage different audio inputs, including sounds with differing noise levels or background interference.
Moreover, the model's prediction proficiency was further validated by real-time evaluations utilizing novel, unencountered audio data. In these instances, the algorithm precisely identified the diseases correlated with each audio input, such as diagnosing COPD from an audio tape with distinctive crackles and wheezes. The analysis of the model's accuracy and loss over time demonstrated a consistent enhancement in performance with each epoch, as loss values diminished alongside the model's increasing confidence in its predictions. The findings were depicted in accuracy and loss graphs, which distinctly illustrated the model's convergence towards ideal performance. The study's results confirm the efficacy of the CNN-based system in delivering a dependable, non-invasive, and efficient approach for diagnosing lung illnesses through respiratory audio signals.
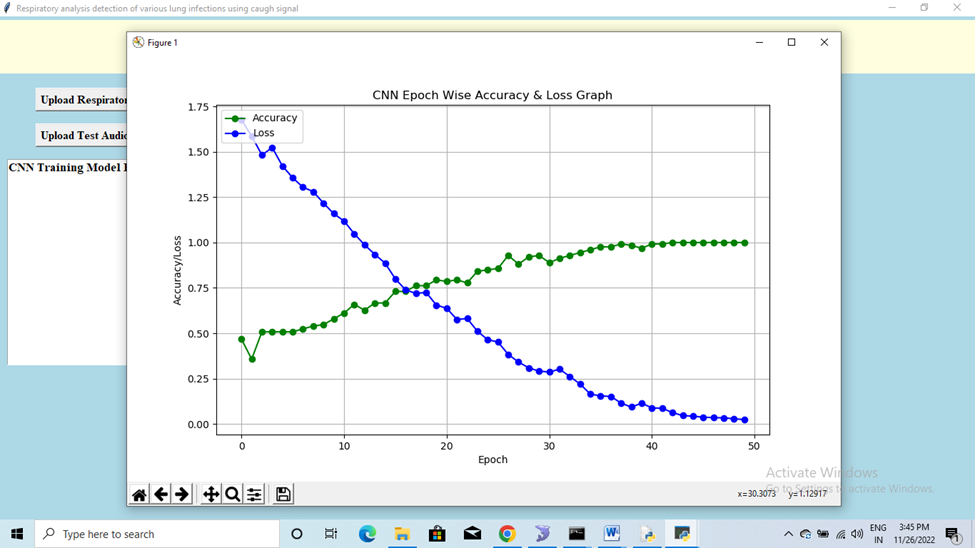
Fig. 4. Results
Conclusion
This study effectively showcased the creation of an efficient and precise method for identifying lung disorders through respiratory audio signals, utilizing convolutional neural networks (CNNs). The non-invasive technology utilizes sophisticated audio processing and machine learning techniques, providing a cost-efficient and accessible substitute for conventional diagnostic approaches such as imaging and manual auscultation. The system\'s capacity to precisely diagnose diseases including asthma, COPD, and pneumonia through audio features derived from lung sounds underscores its potential for early diagnosis and real-time monitoring in clinical environments. The encouraging outcomes, characterized by elevated training accuracy and strong performance on novel data, indicate that this approach may substantially improve respiratory health diagnostics, particularly in resource-constrained or remote settings. Future endeavors may augment the dataset to encompass a broader spectrum of disorders and enhance integration with current healthcare infrastructure for wider implementation.
References
[1] Srivastava, Arpan et al. “Deep learning-based respiratory sound analysis for detection of chronic obstructive pulmonary disease.” Peer J. Computer science, pp.1-22, vol. 7 e369. 2021. [2] Sarkar, M., Madabhavi, I., Niranjan, N., & Dogra, M., “Auscultation of the respiratory system”, Annals of thoracic medicine,” 10(3), 158–168, 2015. [3] Abraham Bohadana, Hava Azulai, et.al.,“Influence of observer preferences and auscultatory skill on the choice of terms to describe lung sounds: a survey of staff physicians, residents and medical students”, BMJ Open Respiratory Research, Vol. 7(1), 2020. [4] Zulfiqar Rizwana, Majeed Fiaz, et.al.,“Abnormal Respiratory Sounds Classification Using Deep CNN Through Artificial Noise Addition,” Frontiers in Medicine, Vol.8, 2021. [5] Proctor J, Rickards E., “How to perform chest auscultation and interpret the findings,” Nursing Times , vol 116(1), pp23-26, 2020. [6] Emmanuel Andres, “Advances and Perspectives in the Field of Auscultation, with a Special Focus on the Contribution of New Intelligent Communicating Stethoscope Systems in Clinical Practice, in Teaching and Telemedicine,” EHealth and Remote Monitoring, 2012. [7] Nishi Shahnaj Haider, “Feature Extraction and Classification Methods for Lung Sounds,” International Journal of Innovative Technology and Exploring Engineering (IJITEE), Vol-10 Issue-1, 2020 [8] Naqvi SZH, Choudhry MA, “An Automated System for Classification of Chronic Obstructive Pulmonary Disease and Pneumonia Patients Using Lung Sound Analysis”, Sensors, vol.20(22), 2020. [9] Jung, S.-Y.; Liao, C.-H.; Wu, Y.-S.; Yuan, S.-M.; Sun, C.-T., “Efficiently Classifying Lung Sounds through Depthwise Separable CNN Models with Fused STFT and MFCC Features,” Diagnostics, 11, 732, 2021. [10] Sovijarvi, “A. Characteristics of breath sounds and adventitious respiratory sounds,” European Respiratory Review, vol 10, pp. 591–596, 2000..
Copyright
Copyright © 2024 P. Praharsha, M. Siva Ganeshan . This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET65182
Publish Date : 2024-11-12
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online